Primer on Softmax
Introduction
Softmax is ubiquitous in Neural Networks. You can find it in the prediction layers of ConvNets applied to computer vision tasks e.g. ImageNet classification on 1000 categories, in the attention mechanism of Transformers and Seq2Seq models but also in econometrics to study effects of variables on a multinomial outcome e.g. how individuals choose health package based on their income level.
Since Softmax is so widely used, it is important to understand all the nuts and bolts of it. In this post, we will first provide intuition about softmax and then go into the details of the math behind it. Finally, we will look at some of the problematic properties of softmax and how to deal with them in practice.
Intuition for Softmax
In the context of Neural Networks, softmax is used to transform the output of a (usually linear) layer into a probability distribution over the classes. Consider the case when we do language modeling ie. predicting the next word in a sentence. We have a vocabulary of $V$ words and we want to predict the probability of each word in the vocabulary being the next word in the sentence conditioned on the previous words. The below chart illustrates this setup: we are trying to predict the next word conditioned on the “The quick brown fox jumps over the lazy” prefix. Using softmax, we get a probability distribution over the vocabulary of words that has a nice statistical interpretation - it is the probability of each word being the next word in the sentence - and we can use this prediction to match the ground truth word and compute the loss. In the next section, we will go into the mathematical details of how softmax works.
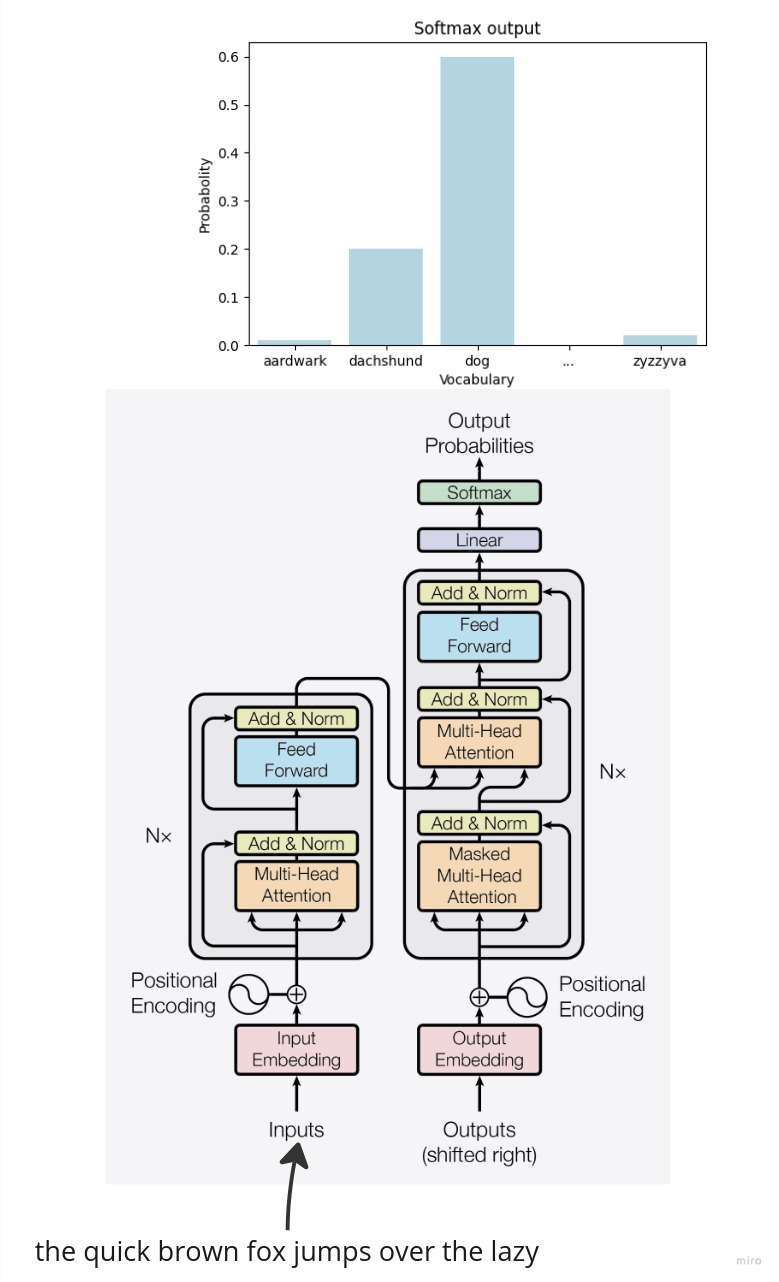
Softmax Definition and Properties
Softmax is defined as follows where $V$ is the size of the vocabulary and $z_i$ is the $i$-th element of the input vector $x$:
\[\text{softmax}(x_i) = \frac{e^{z_i}}{\sum_{j=1}^{V} e^{z_j}}\]It is easy to see that softmax outputs a (categorical) probability distribution over the vocabulary of words since it satisfies the Kolmorogov axioms of probability:
- The probability of an event is a non-negative real number: $\text{softmax}(z_i) \geq 0$. Exponentiation of a real number is always positive and the denominator is also positive since it is a sum of positive numbers.
- Unit measure, the probability of the entire sample space is 1: $\sum_{i=1}^{V} \text{softmax}(z_i) = 1$. This is true because we normalize the numerator by the sum of all the numerators.
- Sigma additivity: $\text{softmax}(z_i) + \text{softmax}(z_j) = \text{softmax}(z_i + z_j)$. This works out, too.
Let’s now see an example. Consider a computer vision scenario where there are 3 classes: cat, dog and horse. We have a linear layer that outputs the following logits for each class and we want to convert these into probabilities using softmax. In the below example, horse has the highest logit and therefore the highest probability of being the correct class.
We can also see that the probabilities are not proportional to the logits. For example, the logit of the horse is 3 and the logit of the cat is 1 but the probability of the horse is 0.67 and the probability of the cat is 0.09. The probability of horse is 7.4 times higher than the probability of the cat (though the logit was only 3 times higher). This is because the exponential function is a very steep function and therefore it amplifies the differences between the scores.
Hence the name softmax: we use a soft version of the (hard) argmax function to pick the highest logit and we use the exponential function to amplify the differences between the scores. The term ‘soft’ is widely used in machine learning to refer to leniency or smoothness. For example, we may want to impose constraints on activations of a neural network layer to be between 0 and 1 due to interpretability reasons but we don’t want to impose it in a hard fashion to help gradient flow. We may then let activations exceed or fall below 0 and 1 but we may penalize it in the loss function. This is called soft constraints.
import numpy as np
import warnings
warnings.filterwarnings('ignore')
logits = np.array([1.0, 2.0, 3.0])
classes = ['cat', 'dog', 'horse']
def softmax(x):
return np.exp(x) / np.sum(np.exp(x), axis=0)
print('Probabilities:' ,softmax(logits))
print('Sum of probabilities: ', sum(softmax(logits)))
Probabilities: [0.09003057 0.24472847 0.66524096]
Sum of probabilities: 1.0
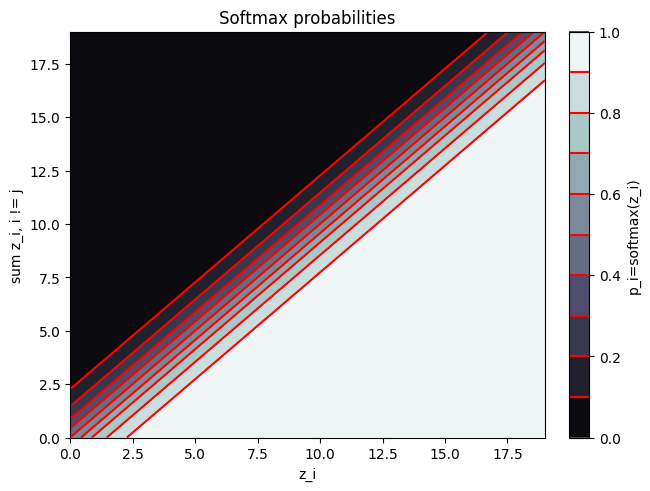
In order to get a better intuition about softmax, consider the below contour plot. The x-axis denotes $z_j$, while the y-axis shows the $\sum_{i\neq j}^{V}z_i$. The contour lines show the value of the softmax function with two arguments: $z_j$ and $\sum_{i\neq j}^{V}z_i$. We are being sloppy here because we assume that
\[\text{exp}(\sum_{i\neq j}^{V}z_i) = \sum_{i\neq j}^{V}\text{exp}(z_i)\]which does not hold, of course. However, this is an okay approximation when the scores are not too far apart. We can see that the softmax function is a steep function that amplifies the differences between the scores and essentially becomes argmax when a score is much higher than the others.
import matplotlib.pyplot as plt
import numpy as np
x = y = np.arange(0, 20, 1)
X, Y = np.meshgrid(x, y)
Z = np.exp(X) / (np.exp(X) + np.exp(Y))
origin='lower'
fig1, ax2 = plt.subplots(layout='constrained')
CS = ax2.contourf(X, Y, Z, 10, cmap=plt.cm.bone, origin=origin)
CS2 = ax2.contour(CS, levels=CS.levels, colors='r', origin=origin)
ax2.set_title('Softmax probabilities')
ax2.set_xlabel('z_i')
ax2.set_ylabel('sum z_i, i != j')
cbar = fig1.colorbar(CS)
# Make a colorbar for the ContourSet returned
cbar.ax.set_ylabel('p_i=softmax(z_i)')
# Add the contour line levels to the colorbar
cbar.add_lines(CS2)
Numerical Stability
It may be tempting to go ahead and implement the softmax as a one-liner in our preferred deep learning framework. However, there is a catch. In practice, we usually compute softmax on an unnormalized vector called logits $z$ which are the outputs of the previous layer.
Quick Aside: Logits
Why do we give the output of the previous layer a special name, logits? It has its roots in statistics. The logits are the inverse of the logistic function, also known as the sigmoid function. The logistic function is used in logistic regression where we model a binary outcome with the linear combination of the coefficients through the sigmoid function. The sigmoid function is defined as follows:
\[\text{p} = \text{sigmoid}(z) = \frac{1}{1 + e^{-z}}\]The inverse of the sigmoid function, the logit, is defined as follows:
\[\text{logit}(p) = \text{sigmoid}^{-1}(p) = \log \frac{p}{1 - p}\]This is why the logit is also called as the log-odds because the odds is defined as the ratio of the probability of an event happening to the probability of the event not happening ie. $p / (1 - p)$. The log-odds is the log of the odds.
In other words, the logit is the input to the sigmoid function. Similarly, we call the input to the softmax function the logits as well. We hope this clarifies the terminology.
Back to Numerical Stability
Going back to the softmax function, we can see that the denominator is the sum of exponentials of the logits. If the logits are large, the exponentials will be even larger and we may run into numerical overflow. Conversely, if the logits are small, the exponentials will be even smaller and we may run into numerical underflow. Let’s take an example of underflow and overflow.
logits_large = np.array([1000., 1000., 1000.])
softmax(logits_large)
array([nan, nan, nan])
logits_small = np.array([-1000., -1000., -1000.])
softmax(logits_small)
array([nan, nan, nan])
So, what is the issue? The logits are the same and thus we expect the probabilities to be the same. However, we get nan’s. This is because the exponentials of the logits are too large and we run into numerical overflow. Numpy is trying to calculate $e^{1000}$ and it is too large to represent as a floating point number (and vica-versa for $e^{-1000}$). Thus, we get nan’s. This causes numerical instability in our computation and we need to fix it.
\[\text{softmax} = \frac{\exp(x_{i})}{\sum_{j=1}^{V} \exp(x_j)}\]Multiply the numerator and denominator by a constant $\exp(-c)$:
\[\text{softmax} = \frac{\exp(x_{i})*\exp(-c)}{\sum_{j=1}^{V} \exp(x_j)*\exp(-c)} \\\]Use the product rule of exponents to simplify the expression:
\[\text{softmax} = \frac{\exp(x_{i}-c)}{\sum_{j=1}^{V} \exp(x_j-c)}\]Now, if we are clever about how we choose $c$, we can avoid numerical overflow. We can choose $c$ to be the maximum of the logits. This way, the largest logit will be 0 and the rest of the logits will be negative. This will ensure that the exponentials of the logits are not too large and we will not run into numerical overflow. Let’s see this in code.
def softmax_stable(x):
z = x - np.max(x)
return np.exp(z) / np.sum(np.exp(z), axis=0)
softmax_stable(logits_large)
array([0.33333333, 0.33333333, 0.33333333])
softmax_stable(logits_small)
array([0.33333333, 0.33333333, 0.33333333])
Our numerically stable softmax implementation managed to tackle both large and small logits.
Pytorch applies the same computation when computing Softmax. You can refer to the C source code. In case you don’t want to read that, here is the docstring of the function for some context:
// Softmax is computed as follows:
// softmax(vi) = exp(vi) / sum(exp(vi))
//
// In order to avoid overflow issues due to exp of a large number, we
// subtract the max of that dim before computing exp.
// softmax(vi) = exp(vi - max(vi)) / sum(exp(vi - max(vi)))
//
// This is implemented as 4 loopnests:
// - First loop computes the max over the softmax dim.
// - Second loop computes exp for every element in v after subtracting
// the max of the softmax dim it belongs to.
// - Third loop computes the sum over the softmax dim.
// - Final loop computes softmax for every element in v.
Fortunately, numpy takes away the struggles of having to do loops but if you just look at the logical steps, you will see that it is the same as the above implementation. Let’s still double check if we get the same results when using pytorch’s softmax.
(SIDE NOTE: Pytorch will actually use a different implementation of softmax, called LogSoftmax with the NLLLOSS , which is more numerically stable. We will review why this is the case in a later section.)
from torch.nn import functional as F
import torch
F.softmax(torch.tensor(logits_large), dim=0)
tensor([0.3333, 0.3333, 0.3333], dtype=torch.float64)
F.softmax(torch.tensor(logits_small), dim=0)
tensor([0.3333, 0.3333, 0.3333], dtype=torch.float64)
Why do we use Cross Entropy Loss with Softmax?
We have seen that softmax converts the logits into probabilities but we still need a loss function to match our predictions with the ground truth. Why is the usual choice of loss function the cross entropy (CE) loss? Let’s investigate.
The cross entropy loss is defined as follows:
\[\text{CE} = -\sum_{i=1}^{V} y_i \log(p_i)\]where $y_i$ is the ground truth probability and $p_i$ is the predicted probability (coming from softmax in this case) of the i-th class. Since we are using one-hot encoding for the ground truth, only the $y_i$ corresponding to the correct class will be 1 and the rest will be 0. Thus, the cross entropy loss simplifies to:
\[\text{CE} = -y_j \log(p_j)\]where $p_j$ refers to the predicted probability of the correct class. Recall that $p_j$ is the softmax of the logit $z_j$ corresponding to the correct class. Thus, we can write the cross entropy loss as a function of the logit $z_j$:
\[\text{CE} = -y_j \log(\frac{\exp(z_j)}{\sum_{i=1}^{V} \exp(z_i)})\]Let’s now take the derivative of the cross entropy loss with respect to the logits $z_j$.
First, apply chain rule (remember $y$ is just a constant):
\[\frac{\partial \text{CE}}{\partial z_j} = -y_j \frac{1}{p_j} \frac{\partial p_j}{\partial z_j} \\\]Use the definition of softmax:
\[= -y_j \frac{1}{p_j} \frac{\partial \frac{\exp(z_j)}{\sum_{i=1}^{V} \exp(z_i)}}{\partial z_j} \\\]Use the quotient rule:
\[= -y_j \frac{1}{p_j} \frac{\exp(z_j) \sum_{i=1}^{V} \exp(z_i) - \exp(z_j) \exp(z_j)}{(\sum_{i=1}^{V} \exp(z_i))^2} \\\]Simplify:
\[= -y_j \frac{1}{p_j} \frac{\exp(z_j)}{\sum_{i=1}^{V} \exp(z_i)} \frac{\sum_{i=1}^{V} \exp(z_i) - \exp(z_j)}{\sum_{i=1}^{V} \exp(z_i)} \\\]Use definition of softmax:
\[= -y_j\frac{1}{p_j} \text{softmax}(z_j) (1 - \text{softmax}(z_j)) \\\]$p_j$ is the softmax of $z_j$:
\[= -y_j (1 - \text{softmax}(z_j)) \\ = \text{softmax}(z_j) - y_j\] \[\frac{\partial \text{CE}}{\partial z_j} = p_j - y_j\]It turns out that the derivative of the cross entropy loss with respect to the logits is the difference between the predicted probability and the ground truth probability. This is quite an interpretable derivative after all. If the predicted probability is close to the ground truth probability, the gradient will be small and the model will not change much. If the predicted probability is far from the ground truth probability, the gradient will be large and the model will change a lot. This is exactly what we want. We want the model to change a lot when it is wrong and change a little when it is right.
We found that using softmax with CE facilitates good gradient flow. Is this the case for other losses, too? Can we think about better alternatives? It is outside of the scope of this post to do an extensive search but let’s explore an alternative, the MAE (mean absolute error). In that case, the loss is defined as:
\[Loss = y_j - \frac{\exp(z_j)}{\sum_{i=1}^{V} \exp(z_i)}\]In other words, the loss is the difference between the ground truth probability and the predicted probability. Let’s now inspect the derivative of the loss with respect to the logits $z_j$:
\[\frac{\partial \text{Loss}}{\partial z_j} = - \frac{\partial \text{softmax}(z_j)}{\partial z_j}\]We can just copy-paste from above:
\[\frac{\partial \text{Loss}}{\partial z_j} = - \text{softmax}(z_j) (1 - \text{softmax}(z_j))\]So, what is the issue here? The pickle is that the derivative can vanish when the predicted probability is close to 0 or 1. This means that the model will not change much when it is wrong and will not change much when it is right. This is not what we want. We want the model to change a lot when it is wrong and change a little when it is right. Generally, it is a good idea to keep in mind the implications of the loss function you are using in relation to prediction layer you are using.
When using the Cross Entropy Loss, our gradients will behave as expected and this is why it is the usual choice of loss function when using softmax.
Why use LogSoftmax and NLLLoss?
We are still not done with all the details of softmax. It would be tempting to just go and use torch.nn.Softmax with torch.nn.CrossEntropyLoss start training and call it a day. This would be a big mistake!
If you look at the docs you will see a note of torch.nn.Softmax:
This module doesn’t work directly with NLLLoss, which expects the Log to be computed between the Softmax and itself. Use LogSoftmax instead (it’s faster and has better numerical properties).
Also, the torch.nn.CrossEntropyLoss docs say it expects raw logits and not probabilities:
This criterion computes the cross entropy loss between input logits and target.
What is still missing? Why is it encouraged to use torch.nn.LogSoftmax with torch.nn.NLLLoss or just feed the raw logits directly to torch.nn.CrossEntropyLoss? Let’s investigate.
Let’s go back to our stable softmax function and consider these input logits:
probs = softmax_stable(np.array([-1., 10., 5000.]))
probs
array([0., 0., 1.])
The stable softmax implementation tackled the large inputs and could produce the correct probabilities. However, the gradients would still not behave as expected. Let’s see why.
In order to calculate the loss, we’ll need to calculate the log of the softmax. Let’s do that
np.log(probs)
array([-inf, -inf, 0.])
We are back to square one because $\text{log}=0$ is not defined. Thus, the log of the softmax is not stable in its current form. We need to fix this. Let’s see how.
The log of the (numerically stable) softmax is defined as where $c=\text{max}(z_i)$:
\[\log(\text{softmax}(z_j)) = \log(\frac{\exp(z_j - c)}{\sum_{i=1}^{V} \exp(z_i - c)}) \\\]By applying the log rule for division:
\[= \log(\exp(z_j - c)) - \log(\sum_{i=1}^{V} \exp(z_i - c)) \\ = z_j - c - \log(\sum_{i=1}^{V} \exp(z_i - c))\]Logically, if we want to recover the softmax, we’ll need to exponentiate the log of the softmax: \(\text{softmax}(z_j) = \exp(\log(\text{softmax}(z_j))) = \exp(z_j - c - \log(\sum_{i=1}^{V} \exp(z_i - c))) \\\)
Now, let’s see how this works out with the logits $z_j$ we had before:
def log_softmax(x):
z = x - np.max(x)
return z - np.log(np.sum(np.exp(z), axis=0))
logs = log_softmax(np.array([-1., 10., 5000.]))
Recovering the softmax:
np.exp(logs)
array([0., 0., 1.])
We just tackled the numerical issue of the log of the softmax. We did this by applying the LogSumExp trick. Again, if you look at Pytorch’s C implementation, you will see that they are using the LogSumExp trick to calculate the log of the softmax:
// LogSoftmax is computed as follows:
// log_softmax(vi) = log(softmax(vi))
// = vi - log(sum(exp(vi)))
//
// Using the same max trick as above:
// log_softmax(vi) = vi - max(vi) - log(sum(exp(vi - max(vi))))
//
// This is implemented as 5 loopnests:
// - First loop computes the max over the softmax dim.
// - Second loop computes exp for every element in v after subtracting
// the max of the softmax dim it belongs to.
// - Third loop computes the sum over the softmax dim.
// - Fourth loop computes log for every element in the sum.
// - Final loop computes the log_softmax for every element in v.
The logsoftmax is not only numerically more stable, but also faster to compute (also stated in the docs). Though there is one more loopnest, we don’t need to exponentiate the logits in the numerator and also we turn a division into a subtraction. These two factors contribute to the speedup.
We now have understand why it is preferred to use logsoftmax. In pytorch, you have 2 options to make use of softmax:
- Use
torch.nn.LogSoftmaxandtorch.nn.NLLLossand feed the logits into the logsoftmax layer - Use
torch.nn.CrossEntropyLossand feed the logits directly into the loss function
Softmax in Transformer Attention Mechanism
Softmax is not only used in the prediction layer of a neural network. It is also used in the attention mechanism of the Transformer. The scaled dot-product attention in Vaswani et. al is defined as:
\[\text{Attention}(Q, K, V) = \text{softmax}(\frac{QK^T}{\sqrt{d_k}})V\]where $Q$ is the query, $K$ is the key, $V$ is the value and $d_k$ is the dimension of the key. The question is: why scaling by $\sqrt{d_k}$? The authors say:
We suspect that for large values of $d_k$, the dot products grow large in magnitude, pushing the softmax function into regions where it has extremely small gradients. To counteract this effect, we scale the dot products by $\frac{1}{\sqrt{d_k}}$.
Recall that the scaling the dot product attention was a key component in successfully training Transformer. Thus, it is essential to understand why scaling is needed.
The authors try to illustrate this via assuming that the entries of $Q$ and $K$ are independent random variables with mean 0 and variance 1. They show that the mean of the dot product is 1 while variance of the dot product is $d_k$.
We can validate their findings by:
\[\mathbb{E}[QK^T] = \mathbb{E}[\sum_{j=1}^{d_k} q_i k_i]\]We assume that the entries of $Q$ and $K$ are independent random variables: \(= \mathbb{E}[Q]\mathbb{E}[K^T] = 0\)
For variance because the entries of $Q$ and $K$ are independent random variables:
\[\text{Var}(QK^T) = \text{Var}(Q)\text{Var}(K^T) = d_k (1^2) = d_k\]If the variation of the dot product scales with the number of dimensions, then it is an issue for the softmax. Recall that softmax amplifies the differences between the logits. If the variance of the dot product scales with the number of dimensions, then the softmax will amplify the differences between the logits and we will end up with a very peaked distribution ie. the softmax essentially turns into an argmax.
This is a problem because gradients will vanish. Recall the derivative of the softmax: \(\frac{\partial \text{softmax}(z_j)}{\partial z_j} = \text{softmax}(z_j)(1 - \text{softmax}(z_j))\)
The below plot shows the derivative of the softmax with respect to $z_j$ at different values of $z_j$:
x = np.linspace(0, 1, 21)
y = x * (1-x)
fig, ax = plt.subplots(1, 1)
ax.scatter(x, y)
ax.set_title('Derivative of softmax(z_i) with respect to z_i')
ax.set_ylabel('Derivative at z_i')
ax.set_xlabel('z_i')
plt.show()
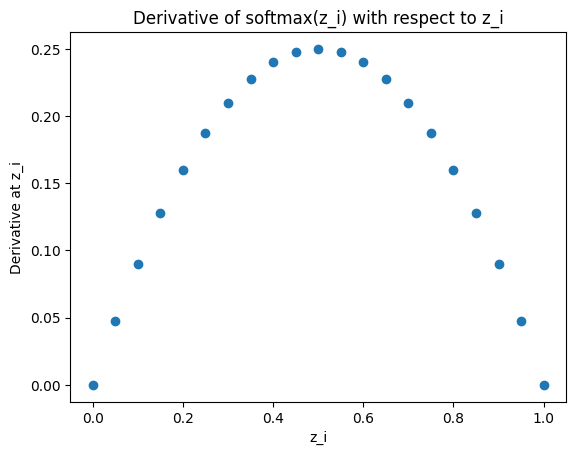
It follows from the plot that when the softmax is very peaked, the derivative is very small for all values of $z_j$ because if one term is close to 1, then the other terms are close to 0. Let’s see how a peaked softmax can result from the unscaled dot product attention. For the sake of simplicity, let’s illustrate this with the dot product attention only at a given position $i$.
import seaborn as sns
torch.manual_seed(0)
d = 512 # usual dimensionality of word embeddings
seq_len = 128 # length of the sequence
softmax = torch.nn.Softmax(dim=1)
# generate unscaled attention weights
q = torch.randn(d, 1) # query vector: only a single query
k = torch.randn(d, seq_len) # key vectors at all positions
a_i_unscaled = torch.matmul(q.t(), k) # unscaled affinity of q to all keys
e_i_unscaled = softmax(a_i_unscaled) # unscaled attention weights
# generate scaled attention weights
q = torch.randn(d, 1) / torch.sqrt(torch.tensor(d))
k = torch.randn(d, seq_len) / torch.sqrt(torch.tensor(d))
a_i_scaled = torch.matmul(q.t(), k)
e_i_scaled = softmax(a_i_scaled)
Let’s take a look at the resulting attention weights for a given position $i$. Below you can see the plot of the attention weights for both the scaled and unscaled dot product attention. As expected, the unscaled dot product attention is very peaked (left) while the scaled dot product attention is more uniform (right).
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
sns.histplot(e_i_unscaled.numpy().flatten(), bins=np.arange(0, 1.1, 0.01), ax=axs[0])
sns.histplot(e_i_scaled.numpy().flatten(), bins=np.arange(0, 1.1, 0.01), ax=axs[1])
title_text = "Max={:.3f}, Min={:.3f}"
axs[0].set_title('Unscaled attention weights | '+title_text.format(e_i_unscaled.max(), e_i_unscaled.min()))
axs[1].set_title('Scaled attention weights | '+title_text.format(e_i_scaled.max(), e_i_scaled.min()))
axs[0].set_xlabel('Attention weight')
axs[1].set_xlabel('Attention weight')
plt.tight_layout()
plt.show()
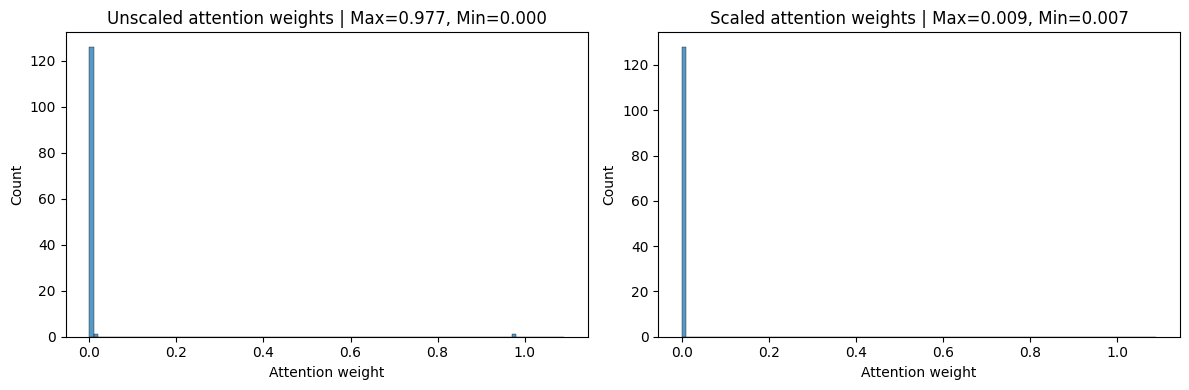
Now, let’s calculate the derivatives of the softmax for both versions. Based on the formula above, we expect the derivative of the unscaled dot product attention to be very small. The below chart shows the derivative of the softmax for both versions head-to-head. While the derivative of the unscaled dot product attention is very small, it is much larger in the scaled version.
# calculate derivative of softmax(z_i) with respect to z_i
unscaled_derivative = e_i_unscaled * (1 - e_i_unscaled)
scaled_derivative = e_i_scaled * (1 - e_i_scaled)
fig, axs = plt.subplots(1, 2, figsize=(12, 4))
sns.histplot(unscaled_derivative.numpy().flatten(), bins=np.linspace(0, 0.01, 100), ax=axs[0])
sns.histplot(scaled_derivative.numpy().flatten(), bins=np.linspace(0, 0.01, 100), ax=axs[1])
title_text = "Max={:.3f}, Min={:.3f}"
fig.suptitle('Derivative of softmax(z_i) with respect to z_i', fontsize=16)
axs[0].set_title(title_text.format(unscaled_derivative.max(), e_i_unscaled.min()))
axs[1].set_title(title_text.format(scaled_derivative.max(), e_i_scaled.min()))
axs[0].set_xlabel('Derivative')
axs[1].set_xlabel('Derivative')
plt.tight_layout()
plt.show()
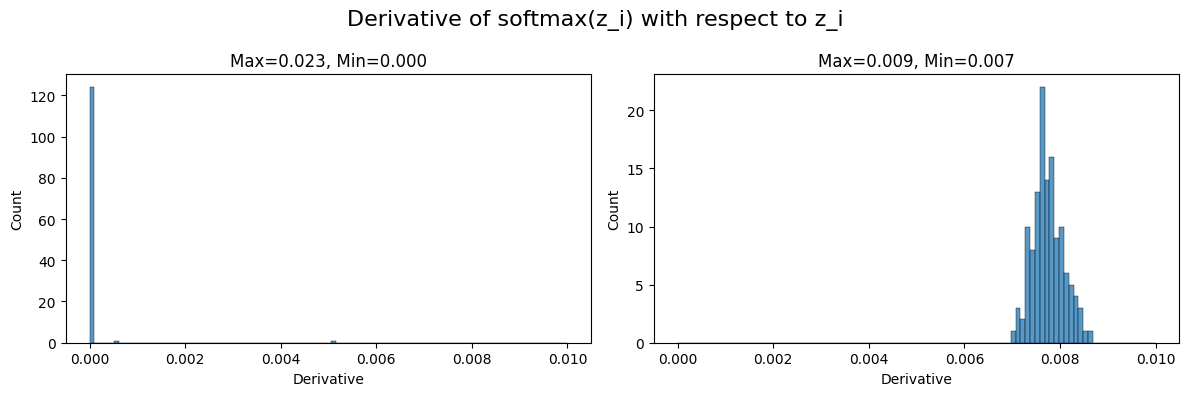
In summary, we have seen that the scaled dot product attention facilitates better gradient flow and now we understand why it was a key ingredient in the success of the Transformer.
Inductive Bias of Softmax
It is a good idea to be aware of the inductive biases of the models we use. These drive the model to exhibit certain behaviors and training dynamics. It is also an important factor when doing alignment research, for instance as in Path dependence in ML inductive biases.
It is useful to discuss the inductive bias of the softmax along with the cross entropy (CE) loss as they are usually used together in the prediction layer of a neural network and as the loss function. In most applications, the CE loss assumes mutual exclusivity, meaning that the target is one-hot encoded, and only incurs loss on the true class. The softmax will pick up on that error signal and will drive the logit of the true class and the logit of the other classes apart. This results in overconfident predictions, meaning that the model will be more likely to assign a high probability to the true class and a low probability to the other classes in the training set which potentially leads to overfitting.
This poses the risk that the model will be overconfident in an out-of-distribution deployment setup. Overconfidence may lead to poorly calibrated models meaning that higher probabilities do not correspond to higher accuracy. Guo et. al [2] explored this on ResNets in computer vision and empirically validated the overconfidence phenomenon. The below chart depicts the accuracy vs confidence for a Resnet and LeNet on CIFAR-100. Notice how peaked the ResNet histogram is and the gap between the accuracy and confidence.
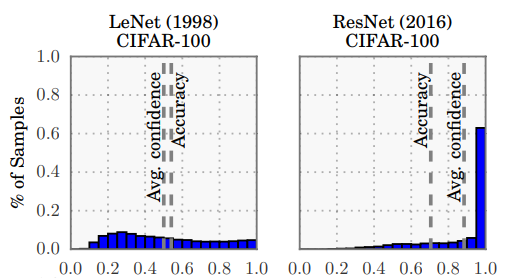
In many deployment scenarios, the application may not only omit the predicted class but also the confidence of the prediction i.e. the predicted probability. Gou et. al point out 2 problematic deployments. In self-driving systems if the car is not confident about its prediction e.g. whether there is a pedestrian in front of the car then it should rely more on other inputs such as the lidar or completely abort and let the driver intervene. In an AI-assisted medical diagnosis scenario, the doctor may not inspect the patient thoroughly if the app says it is 100% sure about the diagnosis.
To mitigate the overconfidence issue, Szegedy et. al [6] introduced label smoothing. Instead of using one-hot encoded labels, they use a smoothed version of the one-hot encoded labels. The smoothed labels are defined as: \(\tilde{y} = (1 - \epsilon) y + \epsilon \frac{1}{K}\)
where $y$ is the one-hot encoded label, $K$ is the number of classes and $\epsilon$ is the smoothing hyperparameter. The authors used $\epsilon=0.1$ on the Imagenet dataset where K=1000. It follows that any class will have the probability of at least $0.1 * \frac{1}{1000}=\frac{1}{10,000}$
Let’s see how label smoothing affects the losses when using CE. In the example below, we have a peaked probability distribution where the true class is predicted at a high confidence, 99%, and all the rest 999 classes equally share the remaining 1%.
We can see that the unsmoothed CE loss is only 0.01 while the smoothed CE loss is 1.159. Label smoothing indeed penalized overconfident predictions.
epsilon = 0.1 # smoothing parameter
p1 = 0.99 # probability of the first class
p_others = np.repeat([(1 - p1) / 999], repeats=999) # probability of the other 999 classes
predictions = np.concatenate([[p1], p_others])
target = np.zeros(1000)
target[0] = 1. # ohe target
smoothed_target = (1-epsilon) * target + (epsilon * (1 / 1000)) # smoothed target using the formula
smoothed_ce = np.sum(- np.log(predictions) * smoothed_target) # cross-entropy loss
unsmoothed_ce = -np.log(p1)
print(f'Unsmoothed CE: {unsmoothed_ce:.3f}')
print(f'Smoothed CE: {smoothed_ce:.3f}')
Unsmoothed CE: 0.010
Smoothed CE: 1.159
Overconfidence can also hurt the decoding process, beam search, in seq-to-seq models. In beam search, we keep track of the cumulative sum of the log probabilities of the tokens in each hypothesis. The hypothesis with the highest cumulative is usually picked. If the model is overconfident, then alternative hypotheses will have a lower cumulative sum and will be pruned. This may result in a suboptimal hypothesis. Probably this is the reason why the original Transformer in Vaswani et. al [2] applied label smoothing. It did hurd perplexity (which is just the exponential of the CE loss) but it did not hurt BLEU score. This makes sense, because we added uncertainty to the labels, so the loss increased but the BLEU score was improved which indicates better hypotheses.
Müller et. al [4] investigated the effects of label smoothing and found that it can indeed improve model calibration but it can hurt distillation (a technique to compress a large model into a smaller one). In summary, label smoothing is a useful technique to mitigate overconfidence but it is not a silver bullet and one should always investigate the effects of label smoothing on the specific task at hand.
Closing thoughts
Sometimes there is much more to a Neural Net layer than meets the eye. In this post, we have seen that the softmax layer is not just a simple normalization layer. It is a layer that has a lot of details and intricacies. It is important to understand the details of the layers you are using in order to be able to use them correctly and to be able to debug your models when things go wrong. I hope you enjoyed this post and that you learned something new. If you have any questions or comments, please drop me an email!
References
[1] The Deep Learning Book, Chapter MLP
[3] On Calibration of Modern Neural Networks
[4] When Does Label Smoothing Help?
[5] https://ogunlao.github.io/2020/04/26/you_dont_really_know_softmax.html
[6] Rethinking the Inception Architecture for Computer Vision