Streaming r/wallstreetbets using AWS
TL;DR
Data are probably the most valuable asset for a hedge fund and they might want to track what is going on at r/wallstreetbets. By creating a data streaming architecture on AWS, you can easily ingest data in a scalable fashion, in real-time. You may then feed them to an NLP model to create valuable features for downstream AI/ML tasks.
Why people might care about streaming r/wallstreetbets? 💸💸💸
The GameStop frenzy was one of the most amazing things that happened lately. In short, what happened, is that a community of traders on Reddit, called the r/wallstreetbets subreddit, realized that hedge funds and other investors shorted GameStop shares. Folks on wallstreetbets realized these positions and started short-squeezing which meant a great money loss for these big institutions and probably survival for GameStop. I am just stunned what such an informal, decentralized community can achieve. Here is an article and a podcast (first like 10 minutes is relevant) link if you want to find out more about this.
Probably at this point you might already think that r/wallstreetbets is something that hedge funds started taking seriously. How can they do that? They could for instance, set up a data streaming solution to track the subreddit in real-time and use NLP to create important features like popularity of a stock. Such features can be fed into a downstream AI/ML model.
Sounds like an overkill? Haha, no. Data are one of the most valuable assets of such institutions because this is what is used to train trading algorithms on. I am not talking about Yahoo Finance Data but like really exotic data sources for example aerial images, social media feed, and so on. The better and richer the data, the more money hedge funds can make. We are speaking millions or maybe rather tens of millions of dollars spent on this asset for a big institution. Having a solution that tracks the (important) moves of r/wallstreetbets seems to be a lucrative solution for such an institution. Actually, the CEO of numer.ai, the coolest hedge fund which runs 100% on AI, mentions in the previously linked podcast that they have folks who create such features for stock market prediction tasks.
If you are still hanging on, let me quickly show you how you can set up the data ingestion part of such a solution. I created a github repo where you find all the code needed.
Tech overview
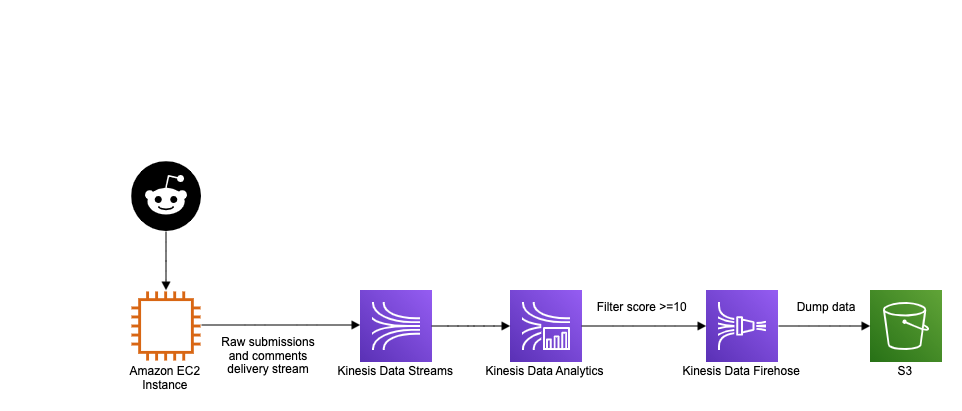
The above diagram shows the AWS architecture of this mini project. The data producer is an EC2 instance that runs a small Python script tutorial.py which uses the Python Reddit API wrapper to query data from Reddit and sends it to the Kinesis Data Stream. Actually, a Lambda function would do just as fine instead of an EC2 instance and you can also enjoy the perks of going serverless. A dummy Kinesis Data Analytics app is built to read from the delivery stream in real time using SQL queries. I just implemented a really dumb app that filters out all comments with less than 10 score. Here, again, you could simply just use a Lambda. The output of this is delivered to Kinesis Data Firehose to persist data in S3.
Implementation details
Here are the steps that are needed to implement the above architecture.
1. Create a reddit app
If you follow along the Quick Start Guide of PRAW, the Python wrapper of the Reddit API, you can get your app credentials in a matter of minutes.
2. Create a Python script to query reddit submissions (posts) and their comments
Querying data via PRAW and submitting it to a Kinesis stream only takes a few lines of code. You could use the tutorial.py in the repo. For the sake of simplicity, I didn’t care about error handling or any other fancy stuff, I just wanted to have a code working to demo this use-case.
3. Set up an EC2 instance with an IAM role that has permissions to create and write to a Kinesis Data Stream
An EC2 instance needs to be spin up with sutiable IAM role, so that EC2 has permission to write to Kinesis. To make things easier, I have created a bootstrap script that:
- Installs git
- Clones my github repo
- Creates a venv and installs dependencies
You need to add this script when configuring (before starting) EC2 at the User Data section. Check the docs for more information.
4. Add your praw.ini to the instance
A praw.ini is PRAW’s config file where, among other things, you can store OAuth options like client_id and password. In the PRAW docs you can find out how to create this config. Btw, there are other ways for authentication like using environment variable. Feel free to use any of them, just make sure you don’t push your secrets to github.
5. Create Kinesis Services
In this architecture, we use Kinesis Data Stream, Analytics and Firehose, too. A Kinesis Data stream can easily be set up from the EC2 instance using the AWS CLI. You might use this command. The rest I chose to set up on the Console but I you could do that using the AWS CLI or maybe boto3, the AWS SDK for Python. You just need to provide the input/output streams, like so Kinesis Data Stream -> Kinesis Data Analytics -> Kinesis Firehose. For the Analytics app, the following sql could be used to filter the comments with at least 10 score in order to focus on what is probably more important.
6. Start python code, lean back and watch 🍿
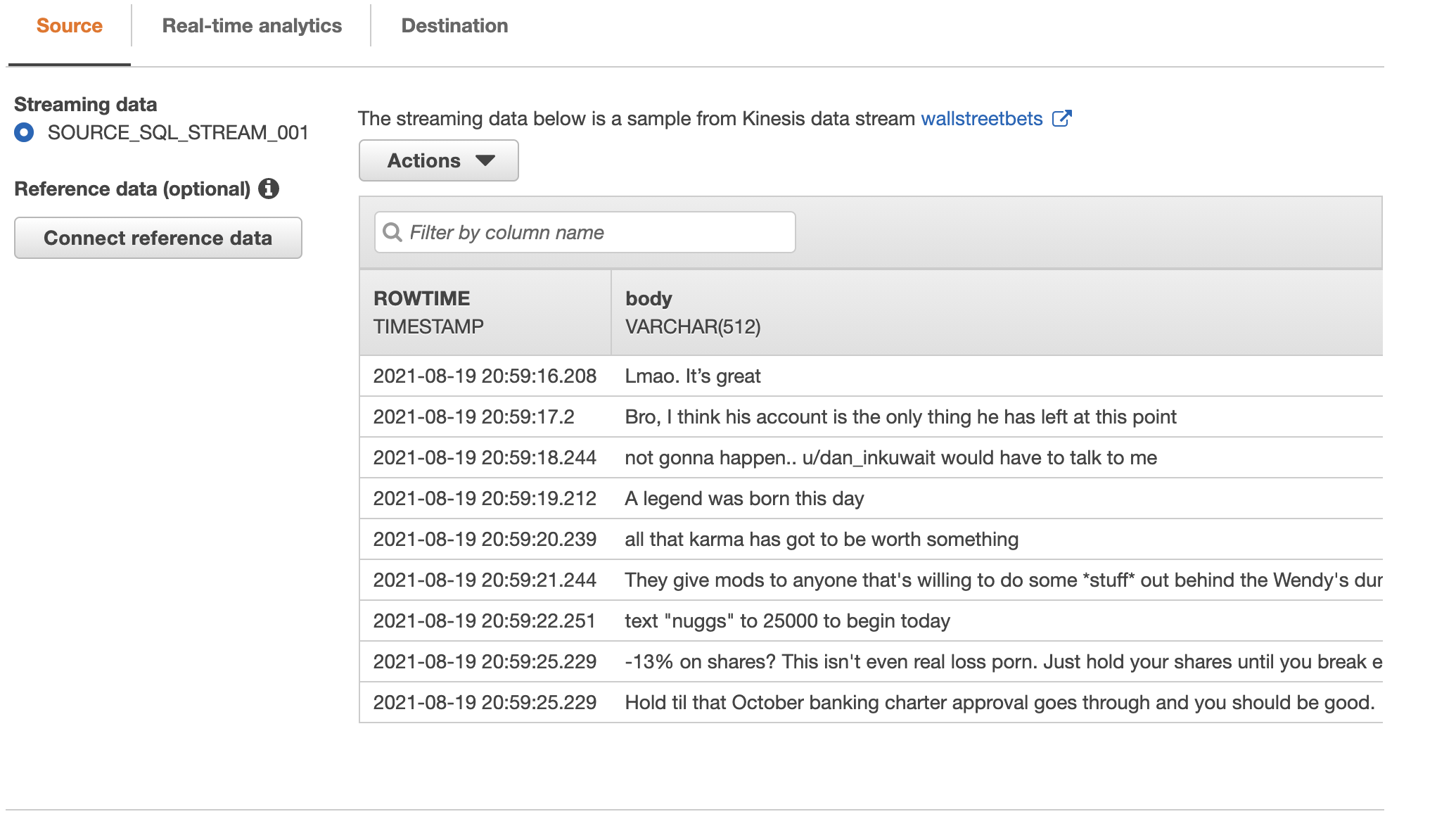
If you wait a few minutes, you will see the raw Reddit comments coming from Kinesis Data Stream to Analytics.
What to do next
In this walkthrough, we have seen how easy it is to set up an AWS solution to stream r/wallstreetbets data. Now that data are within your hands, the question is what you do with them. Since this is text data, chances are an NLP task would be the most useful. We could attempt to turn this vast information into features that downstream AI/ML models can use like what folks on r/wallstreetbets think about a specific share.
You could, for instance, use the NLP service called Comprehend to get out-of-the-box NLP tasks easily done like entity recognition, text classification, sentiment analysis etc.. If you want more customization, you could train an AWS algorithm on your own data. In case you want even more customization, you can write your own, fully-customized algorithm - or BYO (Bring Your Own algorithm) as said in the AWS community, to tackle this task.
Additionally, it would be nice to create a CloudFormation template to automate the setup of resource of this little project.